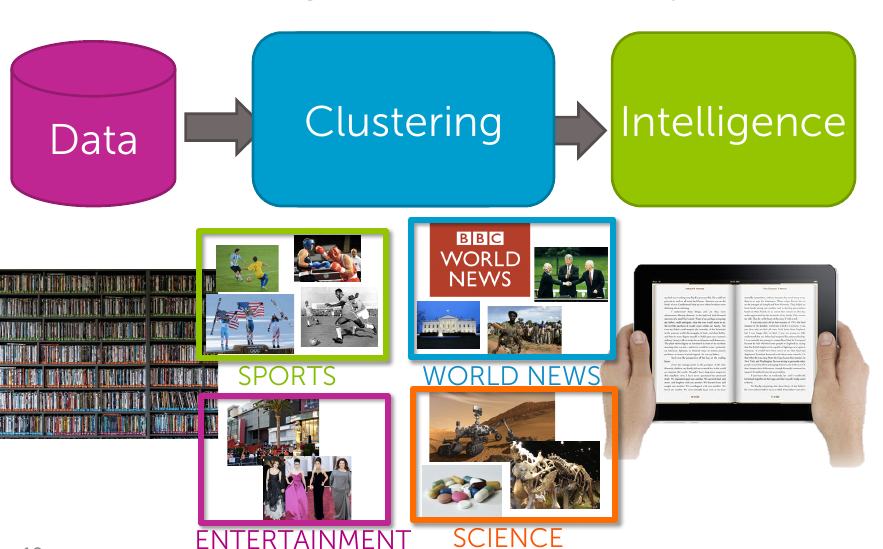
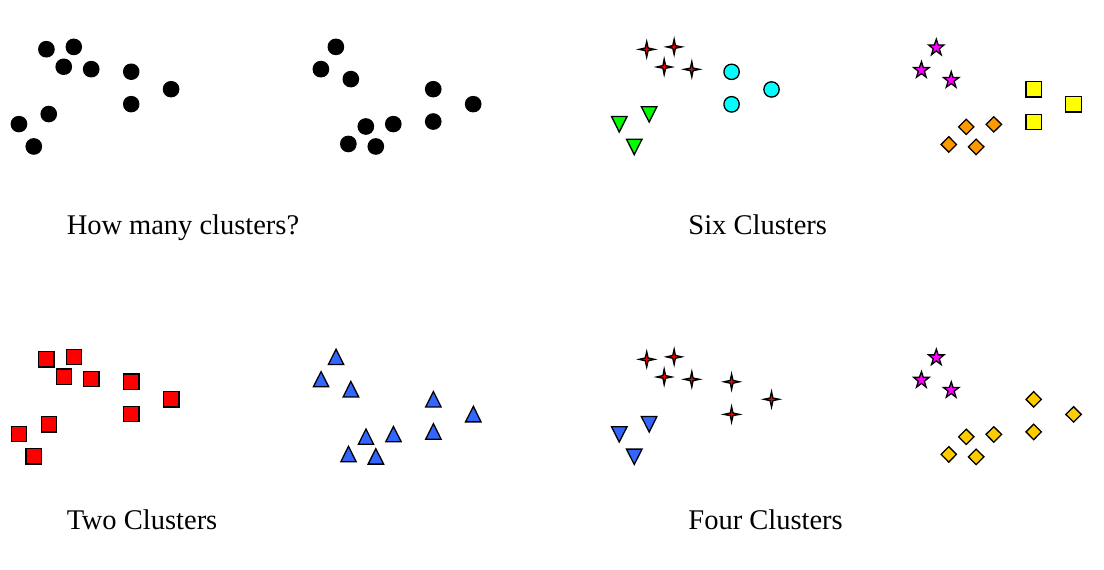
Unsupervised learning task No labels provided Uncovering structure by using only input Input : docs as a vector \(x_i\) Output : cluster labels \(z_i\)
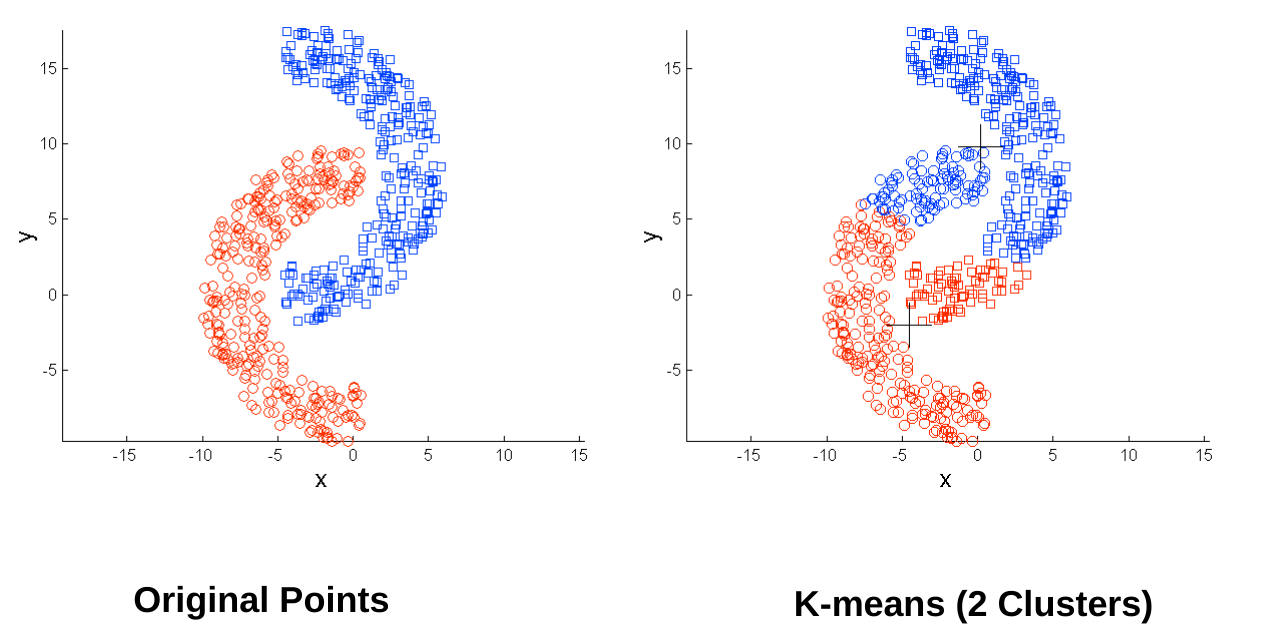
Center and shape Assign observation \(x_i\) (doc) under cluster k (topic label) if Score under cluster k is higher than others Can think of distance from cluster center as a metric
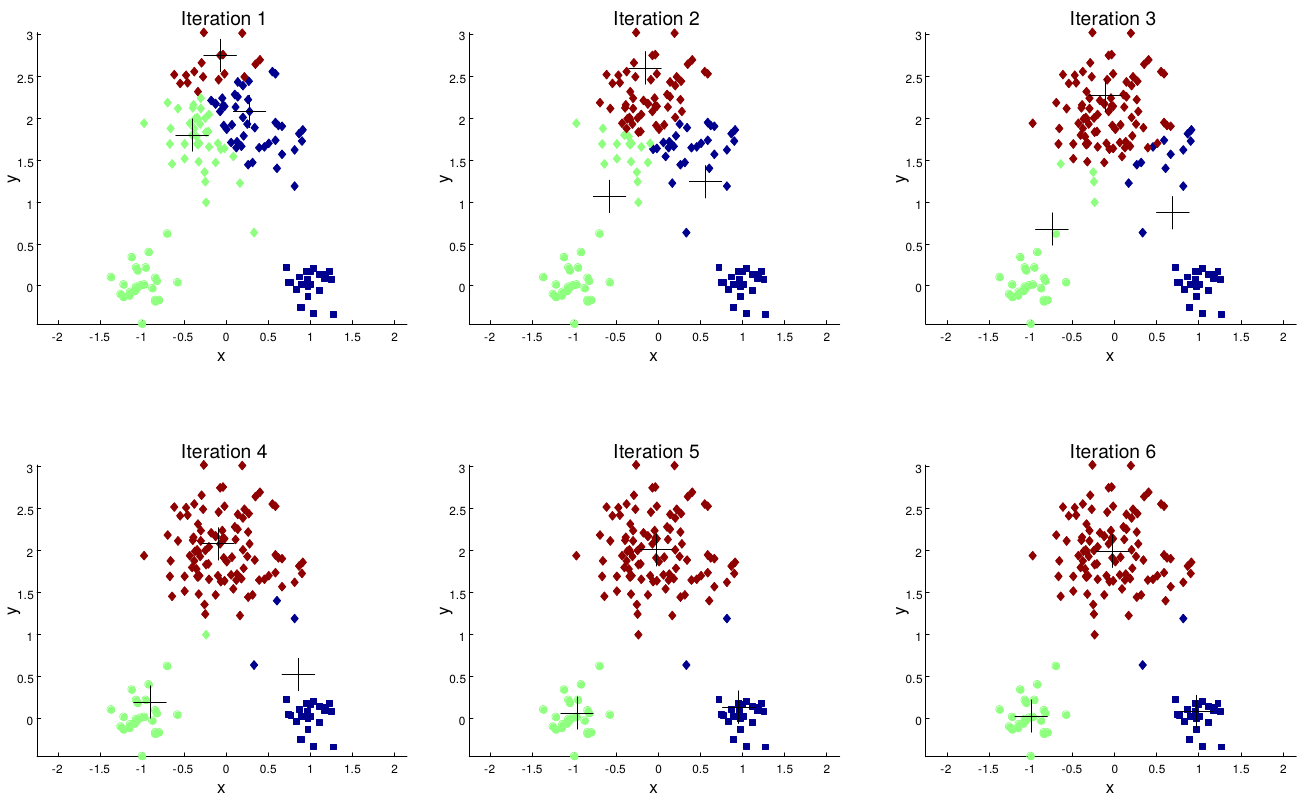
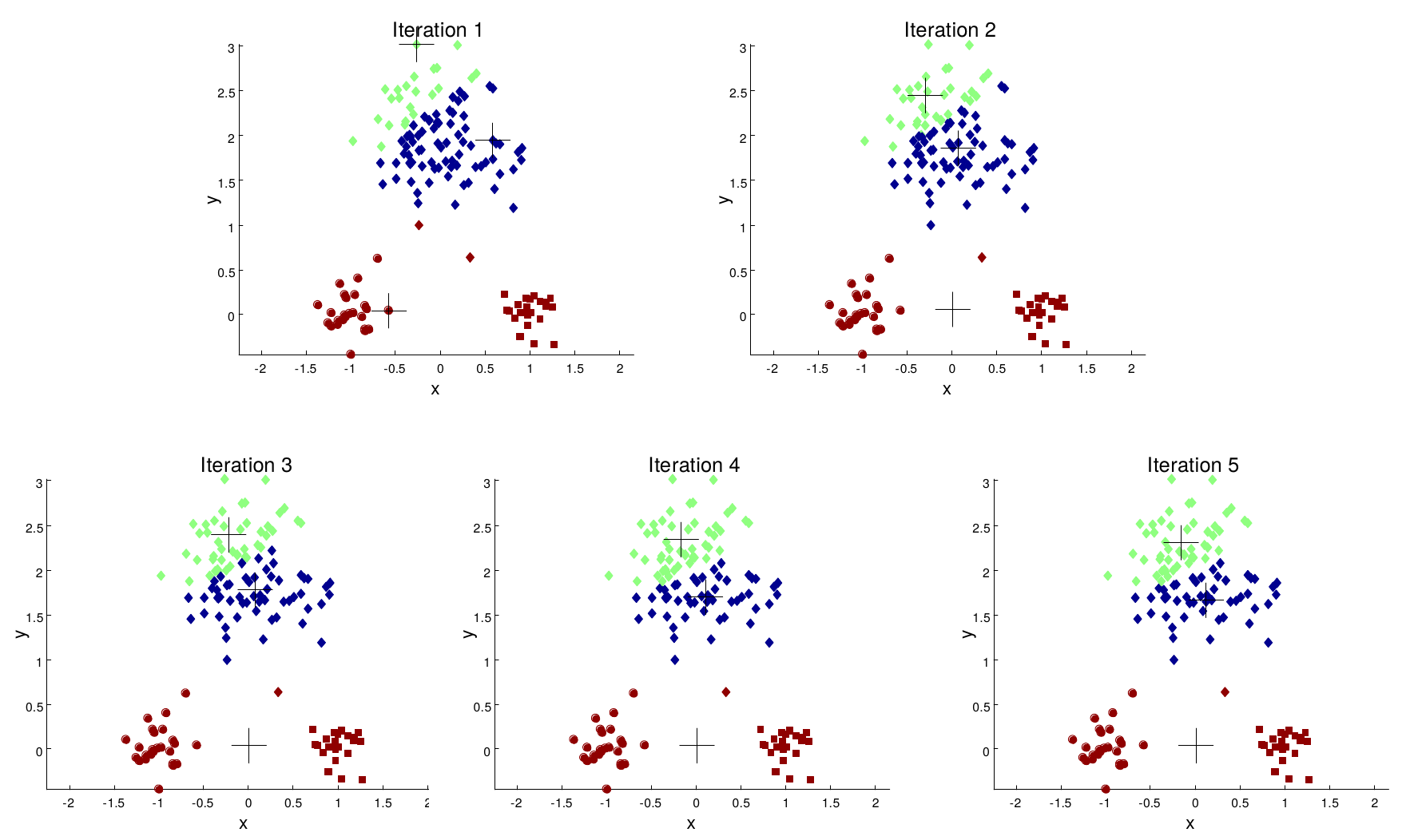
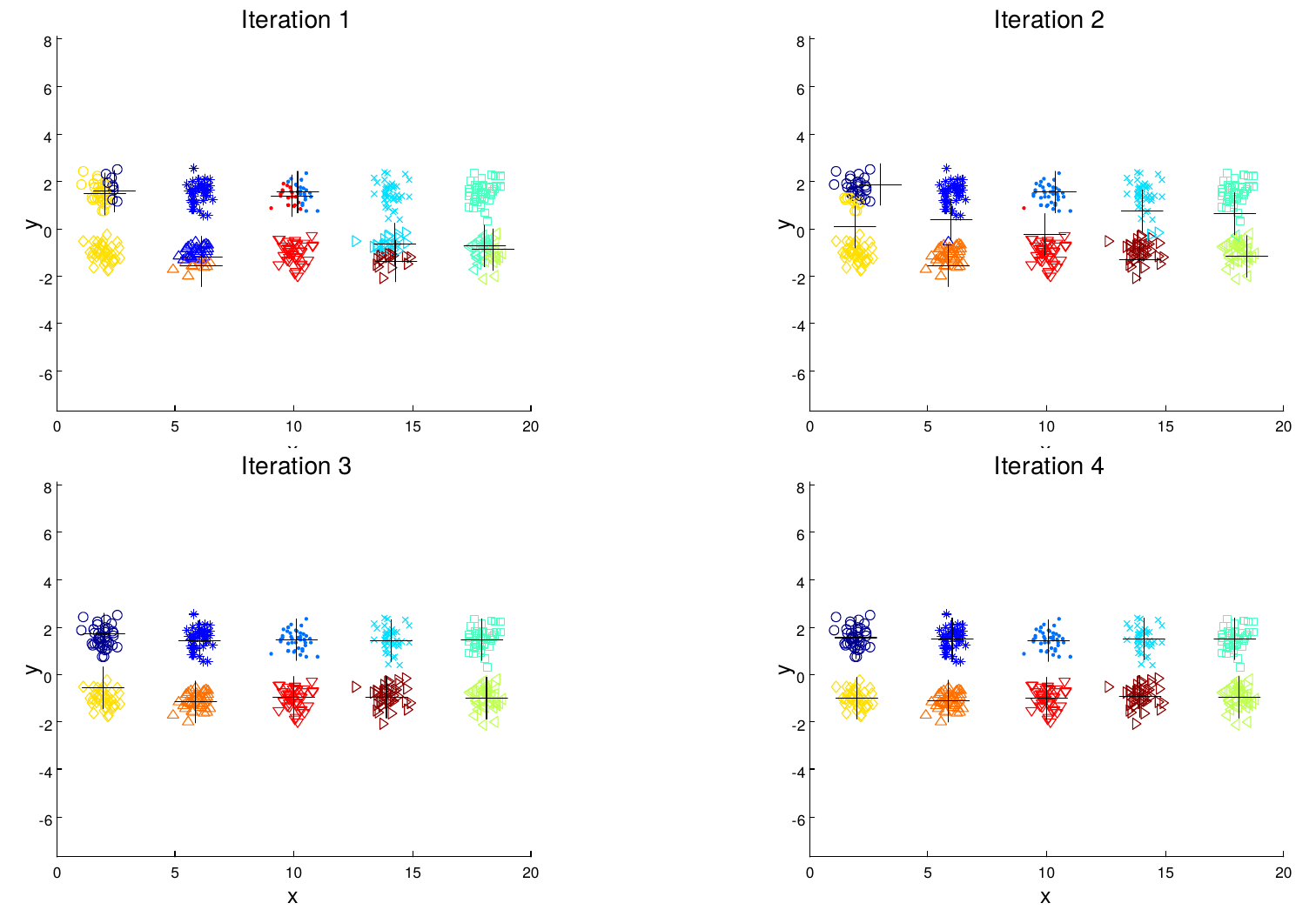
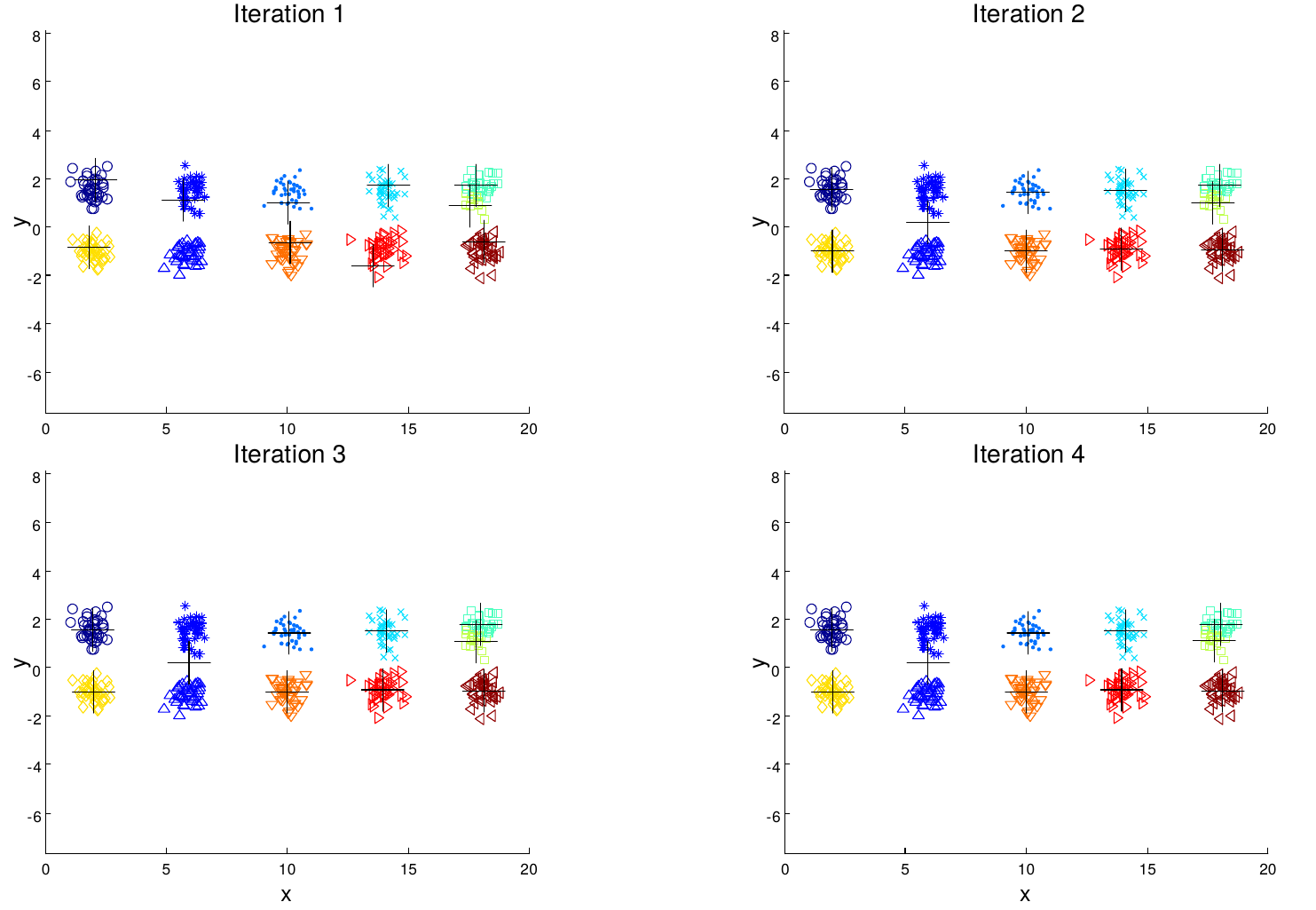
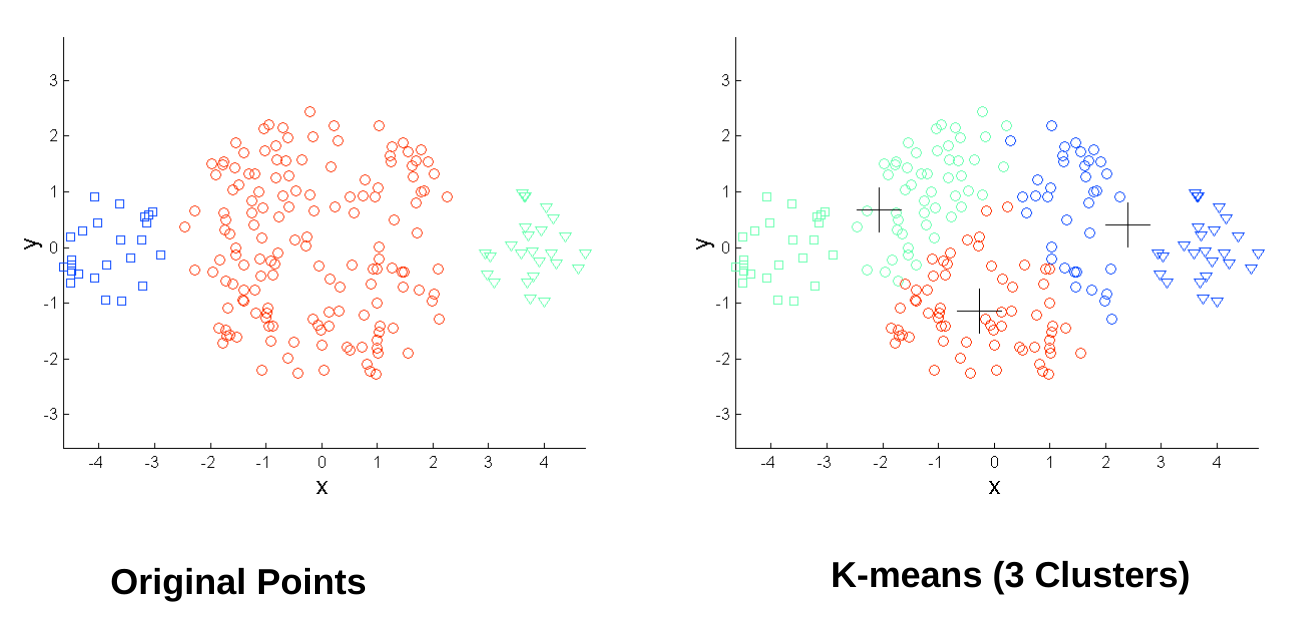
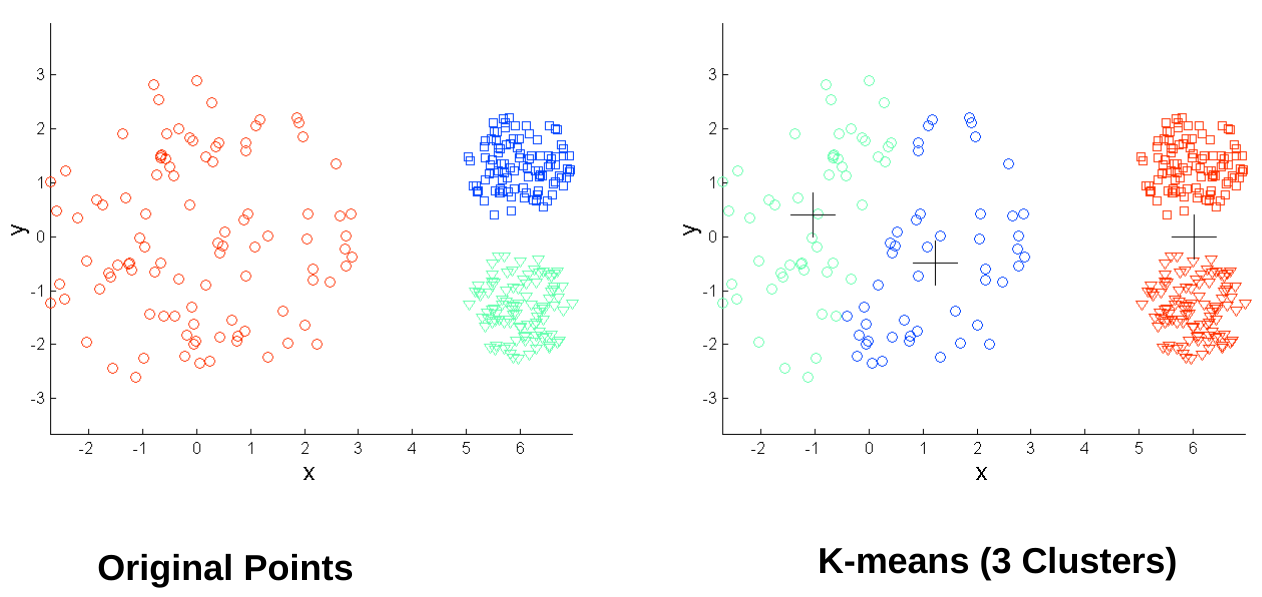
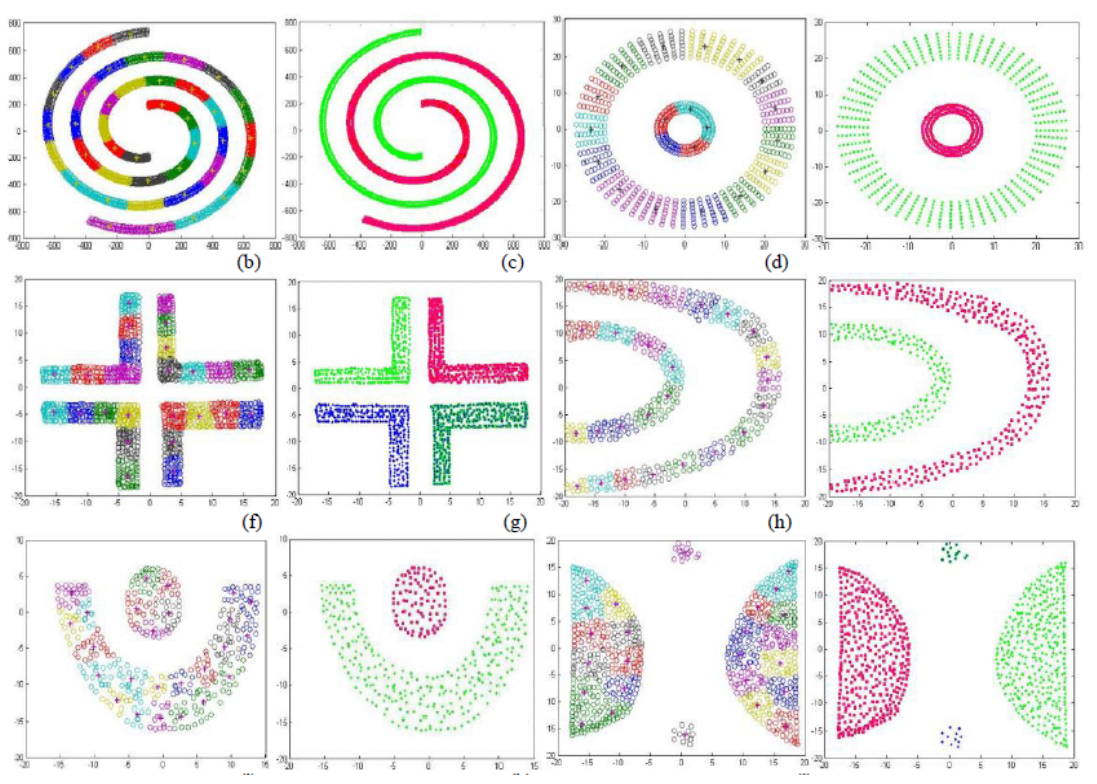
Partitional clustering approach Each cluster is associated with a centroid Number of cluster, K are specified. Select K points as initial centroids. repeat Form K clusters by assigning all points to the closest center Recompute the centroids of each cluster. Until the centroids don't change.
Initial centroids are often chosen randomly. Clusters produced vary from one run to another. ‘Closeness’ is measured by a proximity measure e.g., Euclidean distance, cosine similarity, or correlation. K-means will converge for common proximity measures mentioned above. Most of the convergence happens in the first few iterations.
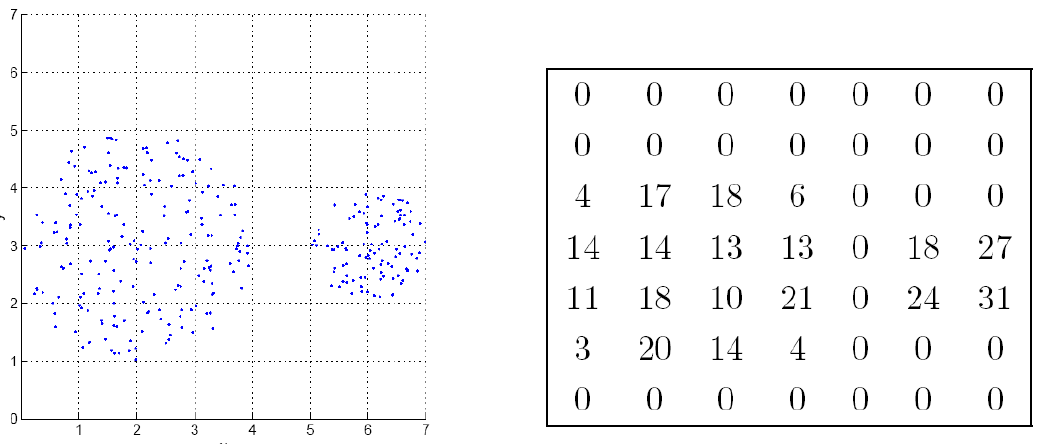
Divide region into a number of rectangular cells of equal volume and define density as # of points in each cell.
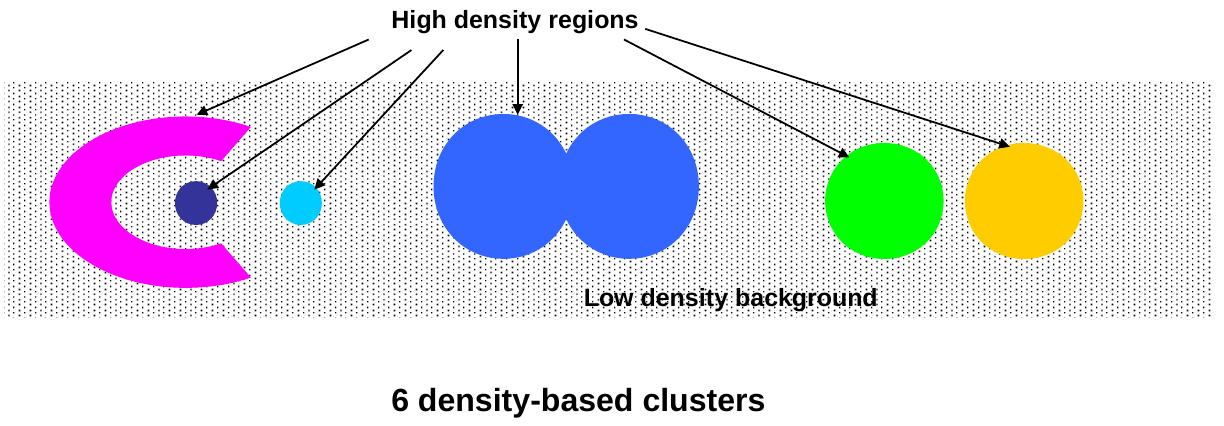
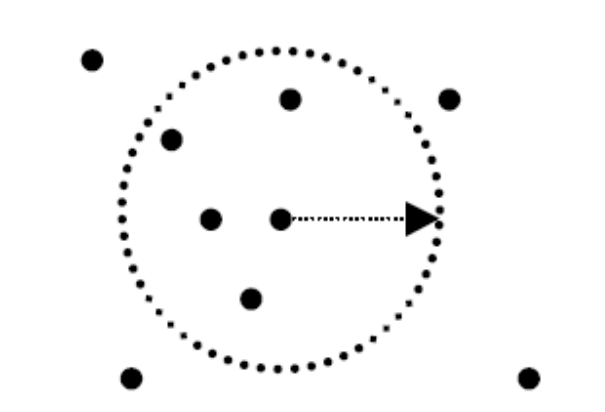
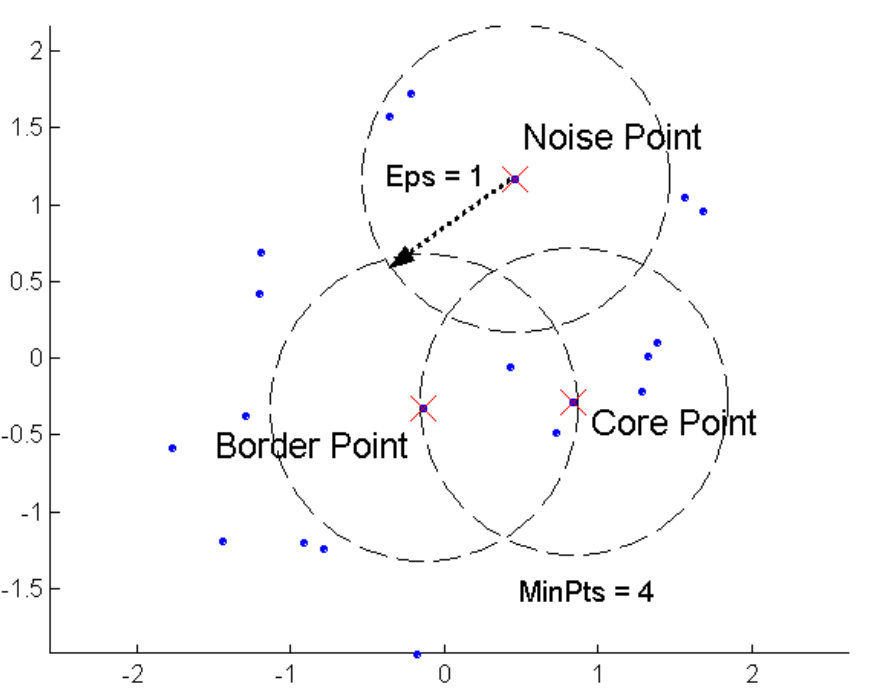
Density = number of points within a specified radius (Eps) A point is a core point if it has more than a specified number of neighbors (MinPts) within Eps. These are points that are at the interior of a cluster. A border point has fewer than MinPts within Eps, but is in the neighborhood of a core point. A noise point is any point that is not a core point nor a border point.
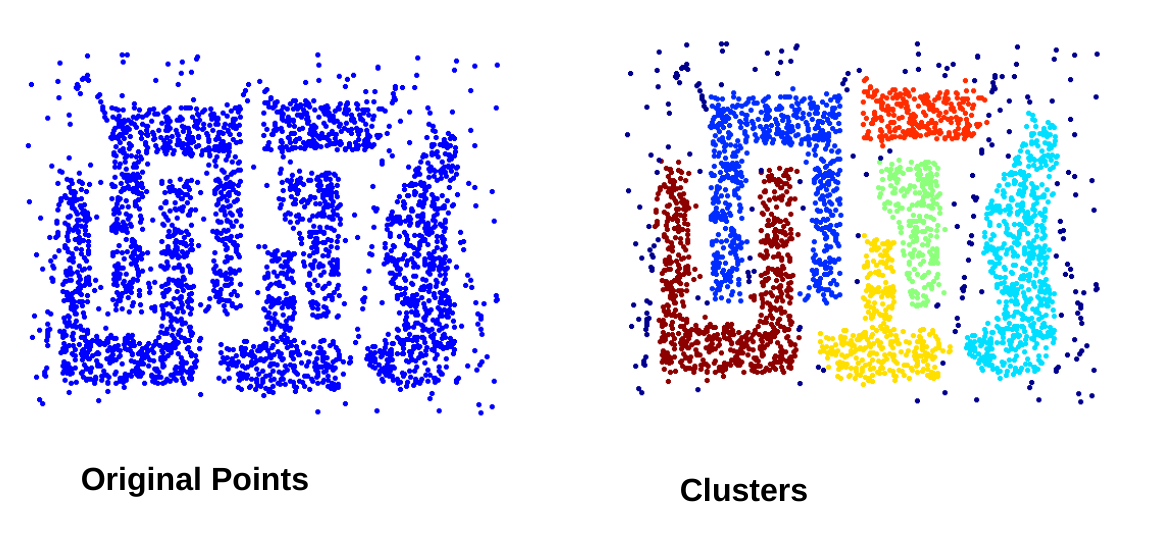
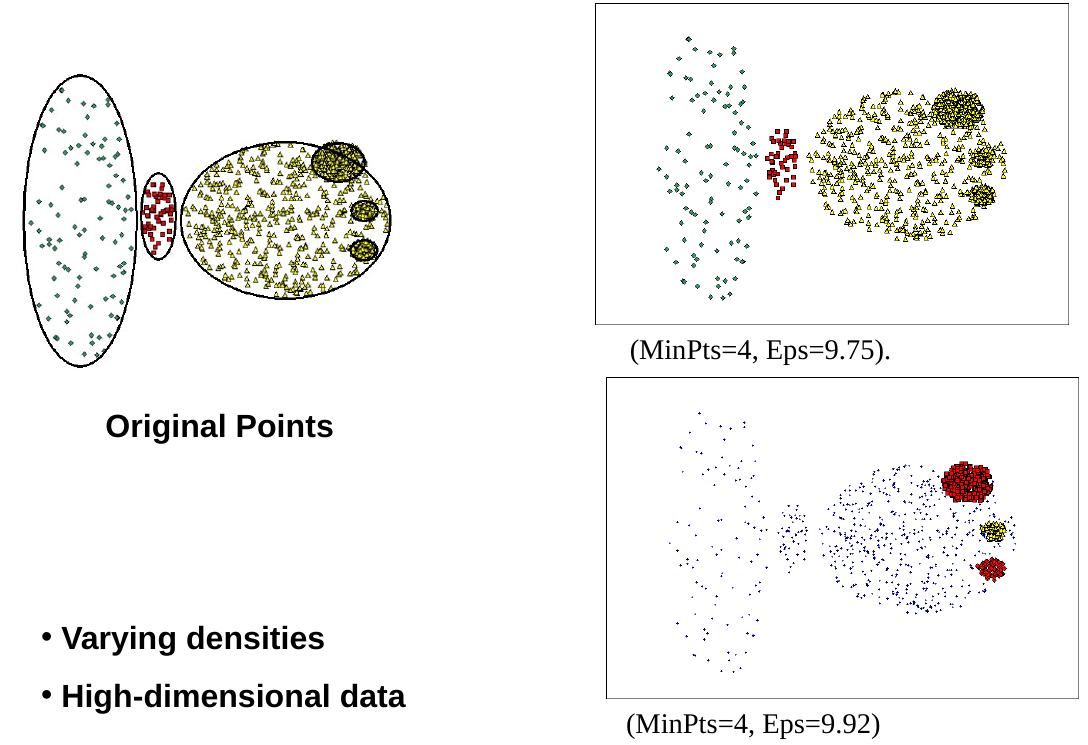
Eliminate noise points Perform clustering on the remaining points Label all points as core, border or noise points. Eliminate noise points. Put an edge between all core points that are within Eps of each other. Make each group of connected points into one cluster. Assign each border point to one of the clusters of its associated core points.